AIツールを再検討してみる(2025年03月05日時点)
はじめに
AIツールをいろいろ試していくうちに、使うツールが変わってきました。現状ので使ってるものをメモしてみます。
コードを書くときに利用するツールの変更
今までは、Visual Studio Code(以後VS-Code)と機能拡張の「GitHub Copilot」を使って、コードを書いていました。以下のような記事を見ながら、設定などしました。
これはこれで便利だしすごかったんですが、たまたま、Xか何かで、「Cody」がいいらしいとの情報を見つけて、プログラマーの人たちからえらく評判がいいらしいし、VS-Codeの機能拡張にもあったので、早速、試してみることにしました。「Cody」は、Sourcegraphが開発している、コードアシストツールだそうです。
今のところお完成ですが、確かんいCodyの方が細かく対応してくれていて、今まで、何回同じプロンプトを打っても改善されない、という現象がなくなった気がします。「Claude 3.7」 Sonnetを利用して、推論みたいな機能が追加されたので、精度があがってる模様。なので、しばらくは、VS-CodeとCodyで試してみようと思います。今のところフリー版ですが、もっと利用するようだったら、Pro版に変えてみようかなと思っています。
リサーチ用のAIツールの再検討
今までリサーチ用では、ChatGPTを使っていたんですが、Felo.aiをテストしてみました。無料でも利用できるんですが、「Pro」版だと、Deep推論が使えるということで「Felo Pro」を契約してします。「DeepSeek R1」や「Claude 3.7 Sonnet」などのモデルが利用できますね。かなり興味深いです。また、調べた結果をまとめてくれるので、単純にGoogle検索するよりも質の高い情報が効率的に得られてる気がします。
Felo.aiを試してみる
試しにFelo.aiに以下を聞いてみました。
「github copilot」と「cody」を比較して、違いは?
全部書こうとするとすごい量になっちゃうので笑、一部きになったところだけ抜粋します。
コンテキスト処理 GitHub Copilot:現在編集中のファイルや関連ファイルからコンテキストを推測し、プロジェクト全体のパターンに沿ったコード提案を行う。 Cody:キーワード検索・コードグラフ分析・複数リポジトリ横断検索を組み合わせ、大規模コードベース全体の関係性を理解して高精度な提案を生成。 実際の性能比較 2023年の実践テストでは、非公開コードベースを用いた10のシナリオ評価で、Codyが9.5/10ポイントを獲得したのに対し、GitHub Copilotは5/10ポイントでした。特にコンテキスト依存度の高いタスク(例:PHP固有の実装提案)でCodyが優位性を示しました。 開発者体験 GitHub Copilot:VS Code/IntelliJとのシームレスな統合に強み Cody:Neovim/Eclipseなど幅広いエディタ対応とローカルLLM(Ollama)連携が特徴 これらの違いから、個人開発者や小規模チームにはGitHub Copilot、大規模企業やマルチリポジトリ環境ではCodyが適する傾向があります。
こうみると、Codyがかなりすごそうだ、というのが十分伝わってきます。。。Google検索を使う頻度、こうやって減っていきそうだなと。
何かコード作ってみようと思ったときに、Felo.aiでリサーチして方法などを見つけて、Codyでプログラミングのアシストしてもらう、というかたちでしばらくやってみようと思います。
【Python】特定のウェブページから画像を取得
今回は、特定のURLから画像データを取得してみたいと思います。VSCodeとGithub Copilotを使っていきます。
どのプログラムを使うのか
いわゆるスクレイピングというやつだと思いますが、Pythonを使えばできるようです。早速ですが、パイセンに聞いてみます。
特定のURLのページから画像を取得したい
以下のコードが返ってきました
import os import requests from bs4 import BeautifulSoup from urllib.parse import urljoin from urllib.request import urlretrieve # 画像を取得するURLを指定 url = 'https://example.com' # ここに対象のURLを入力してください # ページの内容を取得 response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 画像のURLを抽出 img_tags = soup.find_all('img') img_urls = [urljoin(url, img['src']) for img in img_tags if 'src' in img.attrs] # 画像を保存するディレクトリを作成 os.makedirs('images', exist_ok=True) # 画像をダウンロードして保存 for img_url in img_urls: img_name = os.path.basename(img_url) img_path = os.path.join('images', img_name) urlretrieve(img_url, img_path) print(f'{img_name} を保存しました。') print('すべての画像をダウンロードしました。')
コードの改善
保存するときに、ウィンドウを出して場所を指定したいので、以下のプロンプトを追加。
保存する場所はウィンドウを出して指定したい
以下が返答
import os import requests from bs4 import BeautifulSoup from urllib.parse import urljoin from urllib.request import urlretrieve from tkinter import Tk, filedialog # 画像を取得するURLを指定 url = 'https://example.com' # ここに対象のURLを入力してください # ページの内容を取得 response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 画像のURLを抽出 img_tags = soup.find_all('img') img_urls = [urljoin(url, img['src']) for img in img_tags if 'src' in img.attrs] # Tkinterのルートウィンドウを作成して隠す root = Tk() root.withdraw() # 画像を保存するディレクトリを選択するダイアログを表示 save_dir = filedialog.askdirectory(title="画像を保存するディレクトリを選択") if not save_dir: print("保存先が選択されませんでした。") exit() # 画像をダウンロードして保存 for img_url in img_urls: img_name = os.path.basename(img_url) img_path = os.path.join(save_dir, img_name) urlretrieve(img_url, img_path) print(f'{img_name} を保存しました。') print('すべての画像をダウンロードしました。')
コードを説明してくれます
このコードは以下の手順で動作します: 指定されたURLのページ内容を取得します。 BeautifulSoupを使ってHTMLを解析し、すべてのタグを見つけます。 各
タグから画像のURLを抽出し、完全なURLに変換します。 tkinterを使用して保存先のディレクトリを選択するダイアログを表示します。 画像をダウンロードし、選択したディレクトリに保存します。 必要に応じて、URLやその他の設定を変更してください。
コードを試してみる
ウェブページは以下を準備したのでこれを使っていきます。
URLをいれて実行したところ、以下のエラーが出ました。
line 2, in module import requests ModuleNotFoundError: No module named 'requests'
モジュールがインストールされていないため、このエラーが発生しています。以下のコマンドを使用して、requestsモジュールをインストールしてください。と、返ってきて、コマンドも教えてくれるので「pip install requests」を入れて、必要なライブラリをインストールして再実行。うまく動いて、画像を保存できました。

Webページの上から順にダウンロードしてくれてると勝手に思ってたんですが、よく見ると順番がバラバラのようです。上から順に画像を取得して、ファイル名の先頭にカウントをつけるようにパイセンに頼んでみます。
上から順番にDLするように指定
Webページの上から順に画像を取得して、ファイル名の先頭に「000000_」のフォーマットの数字を追加。
以下のコードが返ってきました
#特定のウェブページから画像を取得 by mossan99 import os import requests from bs4 import BeautifulSoup from urllib.parse import urljoin from urllib.request import urlretrieve from tkinter import Tk, filedialog # 画像を取得するURLを指定 url = 'https://mossan99-b.hateblo.jp/entry/2025/02/05/171251' # ここに対象のURLを入力してください # ページの内容を取得 response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 画像のURLを抽出 img_tags = soup.find_all('img') img_urls = [urljoin(url, img['src']) for img in img_tags if 'src' in img.attrs] # Tkinterのルートウィンドウを作成して隠す root = Tk() root.withdraw() # 画像を保存するディレクトリを選択するダイアログを表示 save_dir = filedialog.askdirectory(title="画像を保存するディレクトリを選択") if not save_dir: print("保存先が選択されませんでした。") exit() # 画像をダウンロードして保存 for index, img_url in enumerate(img_urls): img_name = os.path.basename(img_url) formatted_index = f"{index:06d}" # 000000形式の数字を作成 new_img_name = f"{formatted_index}_{img_name}" img_path = os.path.join(save_dir, new_img_name) urlretrieve(img_url, img_path) print(f'{new_img_name} を保存しました。') print('すべての画像をダウンロードしました。')
実行した結果、以下のように出力されました

うまく出力されています!しかし、余分なデータにも番号がついちゃってますね。。。欲しいのは、PNGファイルだけなので、PNGファイルだけ取得するように調整してみます。
png形式のファイルだけ取得するように改善して
パイセンから返事が返ってきます。
コードを実行したら、以下のように出力されました。

無事に出力されました!ひと安心。
やっぱり細かいところが気になる
欲を言うと、ファイル名をWebページの画像の説明文に置き換えたいんですよね。これは次回、やろうと思います。
最終コードは以下に書いておきます。
【Python】PocketのブックマークをNotionにインポートしたい
はてなブックマークはとりあえず問題解決しましたが、実は、Pocketにもブックマークを大量に保存していて、ブックマークが大渋滞しています。
これも解決しようと思います⭐️
Pocketのブックマークがエクスポートできない
アカウントにログインしてみて、エクスポートの項目を探してみましたが、どうにも見つからない。。。調べると以下の情報がありました。ありがとうございます!非常に助かります🙇
結論としては、以下のアドレスにアクセスすればいいようです。なんでこんなわかりづらいことになってるんだろう。。。
アクセスしてみると以下の画面が出ます。
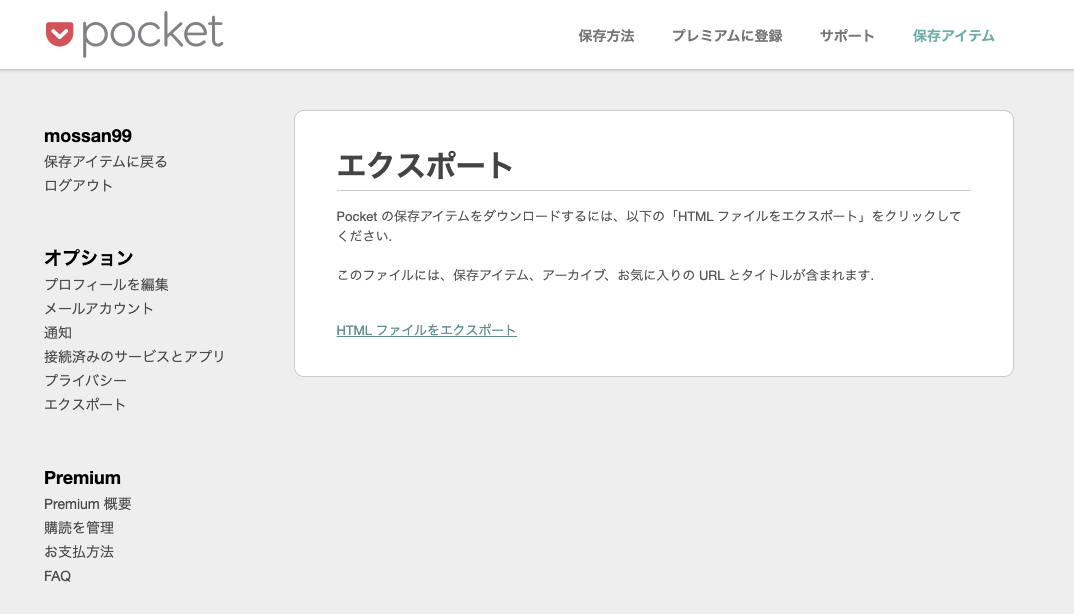
「HTMLファイルをエクスポート」をクリックしてみます。

日本語に翻訳して確認してみます。

何か処理してるようです。後ほど、メールでダウンロードリンクがきました。クリックして、ファイルをDLしたところ、「Pocket.zip」みたいなファイルになっていて、解答したところ、いくつかのcsvファイルになってました。中身はこんな感じ
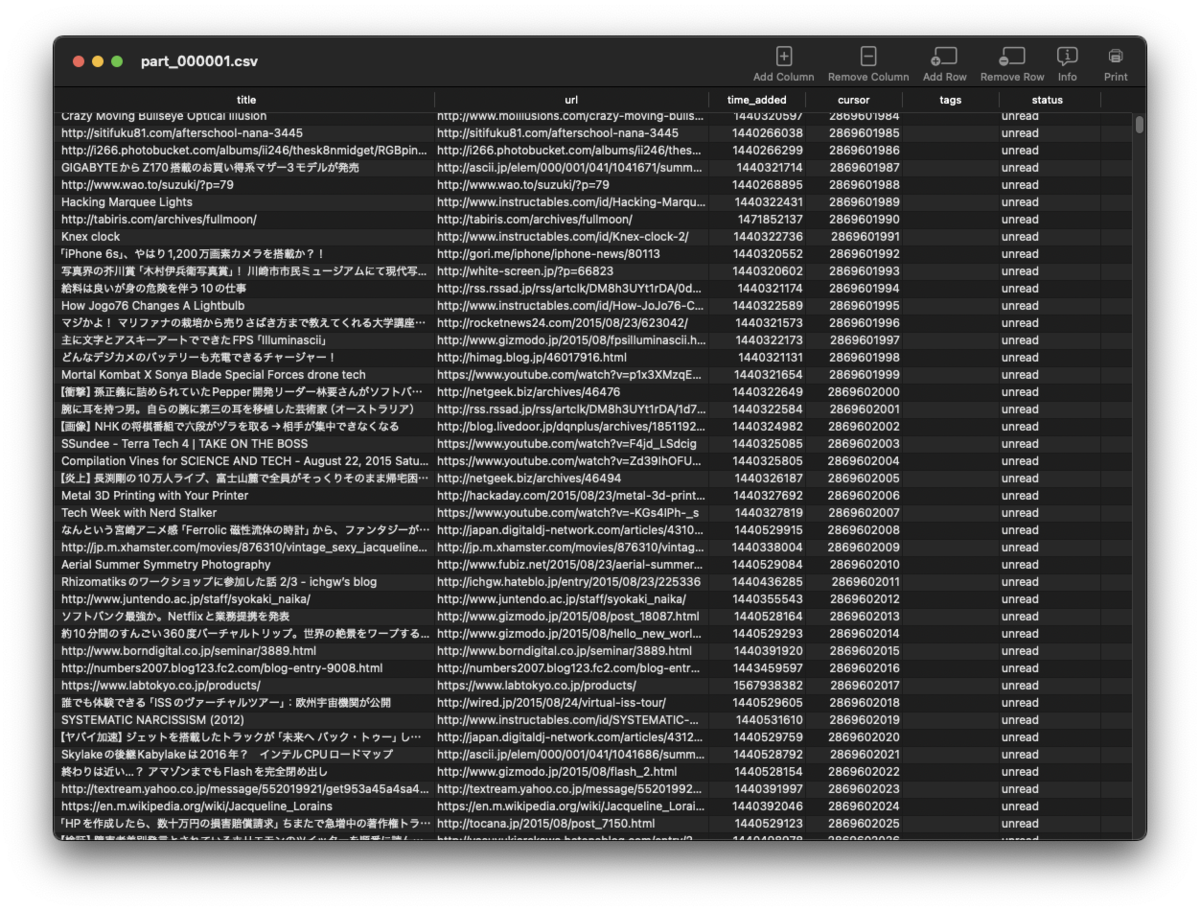
あれ、HTMLファイルじゃないんだ。。。以前、Pocketのブックマークをエクスポートしたときは、HTMLファイルになっていたと思うんですが、改善されたのかもですね。HTML形式で出力されたとしても、前回のはてなブックマークのやり方で何とかいけそうなので、まあ、問題は解決しそう。Notionにも無事にインポートできそうです。
今回は肩透かし感がハンバないですが笑、次回また違うツールを作ってみようと思います。
【Python】はてなブックマークをNotionにインポートしたい
- 手始めに
- Notionとは
- はてなブックマークをhtml形式で保存
- まずはこのままNotionにインポートしてみる
- HTMLからどういうデータを作りたいのか
- Pythonを使って変換する
- 細かいところを調整
手始めに
まずはサクッとやってみようということで、はてなブックマークをエクスポートしてNotionにインポートしてみようと思います。
Notionとは
Notionはざっくり言うとノートアプリとも言えるんですが、非常に多機能で色々な情報が保存できます。
私は記憶するのが苦手で、すっかりメモ魔になっていますが、たまたま、「セカンドブレイン(第2の脳)」の本を読んで感銘を受けまして、色々な情報をNotionに入れて、欲しい時に引き出して活用できれば、記憶力が悪くなろうが何とかやっていけるんじゃないか、と思うわけです。
最近は、「Notion Web Clipper」などで、Notionに直接ブックマークしてますが、過去に保存した、はてなブックマークもNotionに取り込んでみたいな、というのが今回のきかっけです。
はてなブックマークをhtml形式で保存
実際にやってみようとすると、
まずは、はてなブックマークのサイトにアクセスします。
上部のメニューの「設定」をクリックすると、左側にメニューが出てくるので、「データ管理」をクリックするとエクスポートの画面が出てきます。今回は「ブックマーク形式」をクリックして、ブックマークのデータをデスクトップなどに保存します。
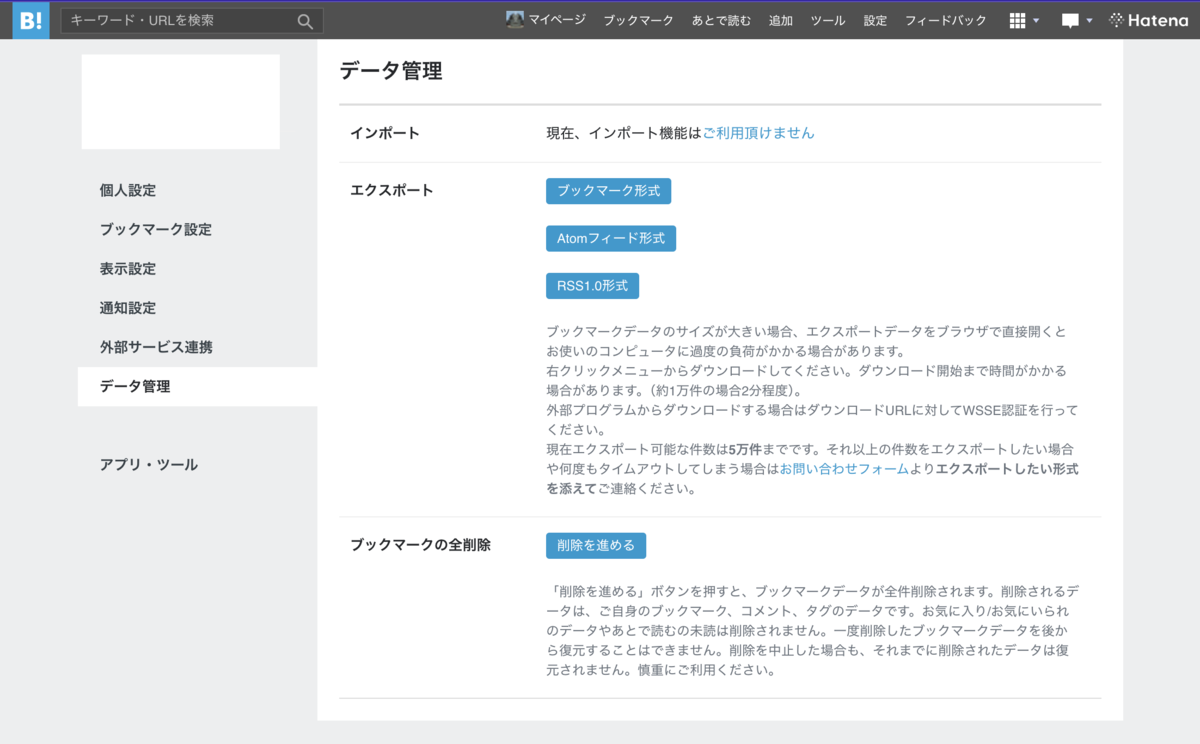
保存されるファイルはhtml形式で、ブラウザで開くと以下のような感じになっていました

ものすご〜くシンプルな、htmlファイルですね。
まずはこのままNotionにインポートしてみる
Notionに取り込むときはNotionの「設定」から「インポート」アクセスすることで、以下のような画面が出てきます。
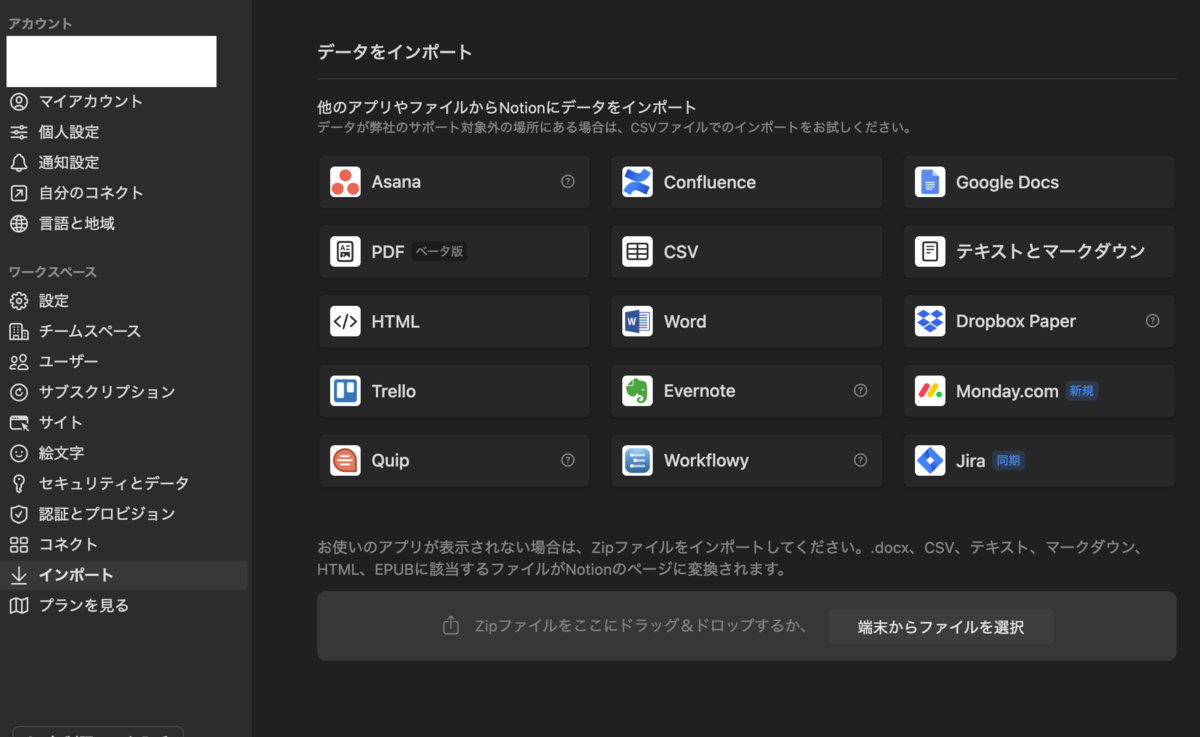
ここの「HTML」を選んでHTMLを選んで取り込めばOK、と言いたいところですが、このままだとブックマークが全部一つにまとまってしまいます。

理想としては、ブックマークを個別にデータベースに収めたいわけです。
HTMLからどういうデータを作りたいのか
HTMLを加工してどういうデータにすればいいか考えてみました。表みたいなものにデータを分けれればよさそうです。
- HTMLからタイトルとURLを分けて表に納める
- ブックマークごとに別の項目にする
表のデータを作るのに一番わかりやすい形式は「CSV形式」のようです。つまり、HTML形式を変換してCSV形式のファイルにして、NotionでCSV形式のファイルを取り込めば問題が解決しそうです。
Pythonを使って変換する
色々調べた結果、Pythonを使えばこのような変換ができることがわかりました。ここでようやくAIパイセンの出番です。VSCodeの設定とか仮想環境とかの説明も必要なんですが、それはまた別の記事で書いてみようと思います。とりあえず準備をして、GitHub Copilotに質問です。以下のように聞いてみました。
htmlファイルを開いて、テキストとURLを分離して、CSVファイルに保存するコードを書いてください。
以下のコードが返ってきました
import csv
from bs4 import BeautifulSoup
# HTMLファイルを読み込む
with open('input.html', 'r', encoding='utf-8') as html_file:
soup = BeautifulSoup(html_file, 'html.parser')
# テキストとURLを抽出する
data = []
for a_tag in soup.find_all('a', href=True):
text = a_tag.get_text()
url = a_tag['href']
data.append([text, url])
# CSVファイルに保存する
with open('output.csv', 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['Text', 'URL']) # ヘッダー行
writer.writerows(data)
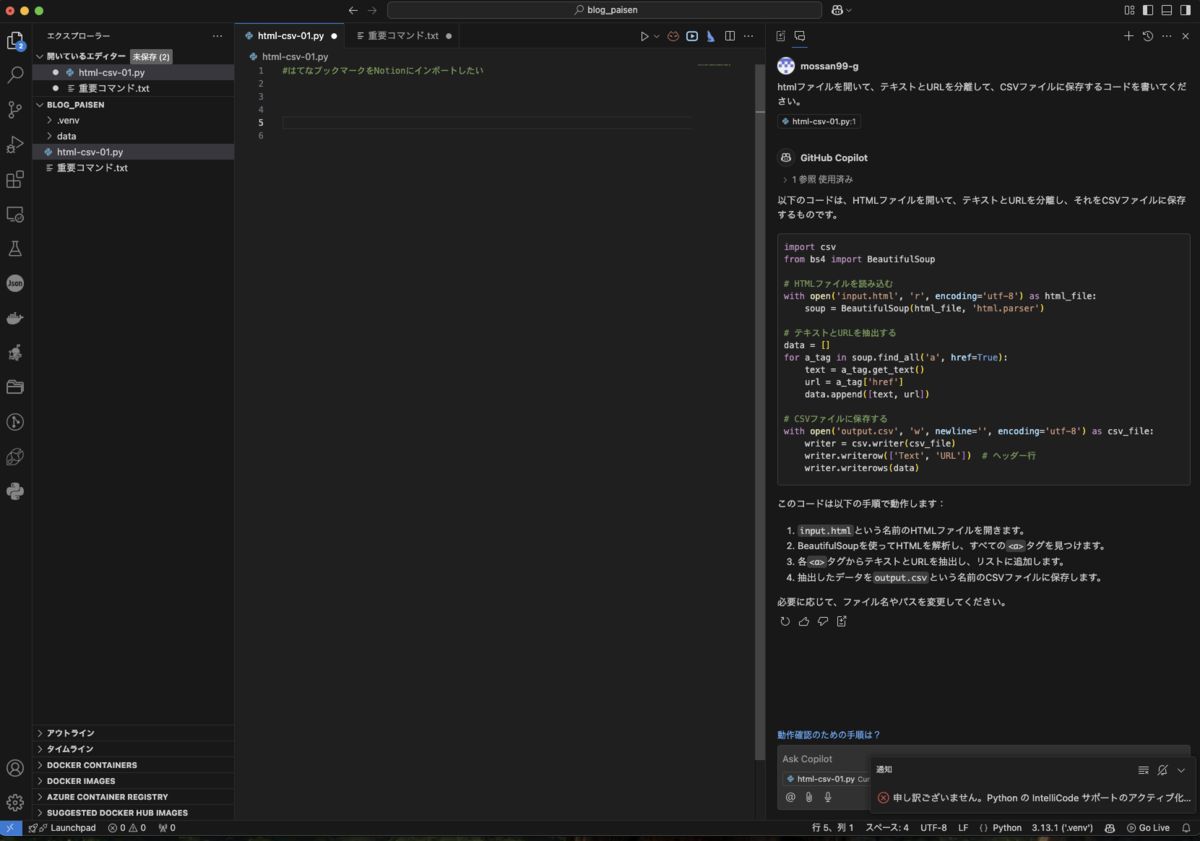
このベースのコードを修正していきます。
ウィンドウが開いてhtmlファイルを選択するように、ウィンドウが開いて、CSVの保存先を指定できるようにしたい
以下のコードが返ってきました
#はてなブックマークをNotionにインポートしたい
import csv
from bs4 import BeautifulSoup
from tkinter import Tk, filedialog
# Tkinterのルートウィンドウを作成して隠す
root = Tk()
root.withdraw()
# HTMLファイルを選択するダイアログを表示
html_file_path = filedialog.askopenfilename(title="HTMLファイルを選択", filetypes=[("HTML files", "*.html")])
if not html_file_path:
print("HTMLファイルが選択されませんでした。")
exit()
# HTMLファイルを読み込む
with open(html_file_path, 'r', encoding='utf-8') as html_file:
soup = BeautifulSoup(html_file, 'html.parser')
# テキストとURLを抽出する
data = []
for a_tag in soup.find_all('a', href=True):
text = a_tag.get_text()
url = a_tag['href']
data.append([text, url])
# CSVファイルの保存先を選択するダイアログを表示
csv_file_path = filedialog.asksaveasfilename(title="CSVファイルの保存先を選択", defaultextension=".csv", filetypes=[("CSV files", "*.csv")])
if not csv_file_path:
print("CSVファイルの保存先が選択されませんでした。")
exit()
# CSVファイルに保存する
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['Text', 'URL']) # ヘッダー行
writer.writerows(data)
print(f"データが {csv_file_path} に保存されました。")
試しに実行したら、以下のエラーが出ました
from bs4 import BeautifulSoup
ModuleNotFoundError: No module named 'bs4'
これをそのままプロンプトに打ち込んでみたら、以下の返答がきました
モジュールがインストールされていないため、このエラーが発生しています。以下のコマンドを使用して、bs4モジュールをインストールしてください。
pip install beautifulsoup4
ターミナルでこのコマンドを実行することで、bs4モジュールがインストールされ、エラーが解消されます。
とのことなので、ターミナルに打ち込んでインストールして、再実行してみます。
ファイルの保存場所が指定されるので保存して、CSVファイルの中身をみてみます。
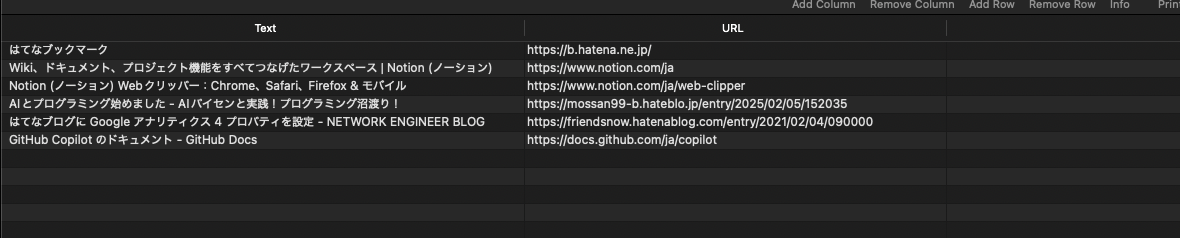
無事に変換してるっぽい!すごい!
細かいところを調整
とりあえず動いてホッとしたんですが、細かいところが気になってしまうのが私の悪いクセ😅というわけで、改善したい部分をリストアップしてみます。
- HTMLを選ぶ前に「HTMLファイルを選択してください」というメッセージを出したい
- CSVファイルを保存するときに、「CSVファイルを保存してください」というメッセージを出したい
- CSVファイルの名前は、HTMLファイルと同じにしたい。
以下、プロンプトに入れて、コードをさらに調整していきます。今回は、全部一気に入れるとエラーがでそうなので、ひとつずつ入れていって、最終版のコードが何とかできました!
最終コードは、有料のところに入れておきます。。。すいません🙇といっても、ここまで実践したら、同じコードができてると思いますが。。。
コードを実行して、ようやくCSVファイルができたので、NotionにこのCSVファイルをインポートしてみます。
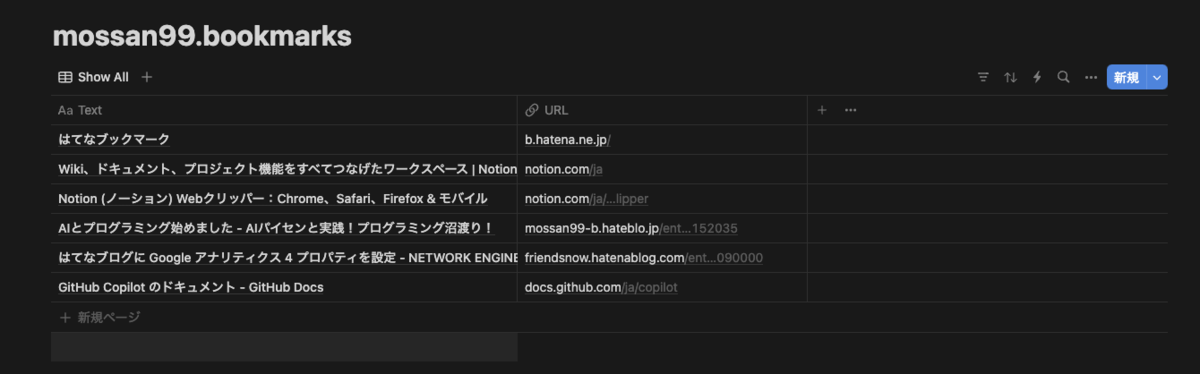
おーいい感じ!ここまでできれば、あとはNotionで何とかなりそうです。
サクッとやるつもりが意外と時間かかっちゃいましたが、プログラムが無事に動くとかなりテンション上がりますね!!!こんな感じで、便利になりそうなツールを作ってみようと思います。
以下に最終コードを書いておきます。